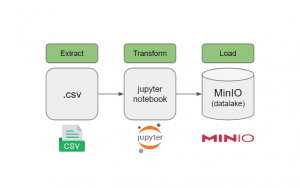
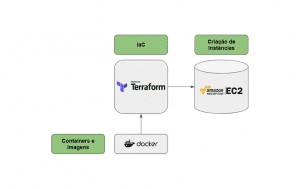
Detalhes do projeto
- Link do projeto no Github: https://github.com/cerqueiralex/etl-pyspark-sqlite-docker/
- Tecnologias: Python, PySpark, SQLite
- Categorias: Data Engineering, ETL
Neste projeto, compartilharei o passo a passo de um projeto de processamento de dados em lote que utilizei em meu portfolio. O objetivo era transformar um arquivo JSON em um banco SQLite, utilizando PySpark e Docker.
1. Configurando o ambiente com Docker Compose
Comecei criando um cluster PySpark em Docker com três containers: um master, dois workers e um history para armazenar logs. Utilizei o Docker Compose para facilitar a configuração e o gerenciamento do cluster.
2. Gerando a base de dados SQLite
Em seguida, desenvolvi dois scripts Python:
- Gerador de dados: Este script gerou um arquivo JSON com dados fictícios, simulando um cenário real.
- Criador da base de dados: Este script criou a base de dados SQLite e definiu a conexão com o arquivo JSON gerado.
3. Implementando o job ETL com PySpark
O job ETL foi escrito em PySpark e implementado no container master do cluster. As principais etapas do job foram:
- Leitura do arquivo JSON: O arquivo JSON gerado no passo 2 foi lido como um DataFrame do Spark.
- Definição do schema: Um schema foi definido para garantir a consistência dos dados na base SQLite.
- Tratamento de dados: O campo de e-mail foi tratado para remover caracteres inválidos e garantir a padronização.
- Gravação na base SQLite: O DataFrame final foi gravado na base SQLite criada no passo 2.
4. Executando o job ETL
O job ETL foi executado no container master do cluster através do comando spark-submit. O processo de execução foi monitorado no console do container.
5. Resultados e Considerações
O job ETL foi executado com sucesso, transformando o arquivo JSON em um banco SQLite. A utilização do PySpark e do Docker proporcionou um ambiente escalável e eficiente para o processamento de dados.
Pontos importantes do projeto:
- Utilização do Docker Compose para facilitar a configuração do cluster PySpark.
- Desenvolvimento de scripts Python para gerar a base de dados SQLite e o arquivo JSON.
- Implementação do job ETL em PySpark com leitura de dados, definição de schema, tratamento de dados e gravação na base SQLite.
- Execução do job ETL no container master do cluster e monitoramento do processo.
Conclusão:
Este projeto demonstra como o PySpark e o Docker podem ser utilizados para realizar o processamento de dados em lote de forma eficiente e escalável. A utilização de containers facilita a configuração do ambiente e o deploy do job em diferentes plataformas.
Este projeto foi realizado para fins de estudo e demonstração de habilidades. O código-fonte e os dados utilizados estão disponíveis em meu repositório GitHub.