O Aprendizado de Máquina (Machine Learning, em inglês) representa um subcampo da Inteligência Artificial que capacita máquinas a aprenderem com dados, substituindo a programação explícita. Em síntese, os algoritmos de aprendizado de máquina permitem que sistemas realizem previsões ou tomem decisões fundamentadas em dados, evoluindo automaticamente com a experiência adquirida.
Aplicações Pioneiras
O aprendizado de máquina tem vasta aplicabilidade, desde sistemas de recomendação online até diagnósticos médicos e veículos autônomos. Outras áreas incluem processamento de linguagem natural, visão computacional e análise de sentimentos em textos.
Desafios e Considerações
Apesar das amplas aplicações, desafios como overfitting, viés nos dados e complexidade computacional persistem. Reconhecer esses fundamentos é crucial para explorar eficazmente temas avançados e aplicar técnicas de maneira eficiente em projetos próprios.
Diversidade nos Tipos de Aprendizado de Máquina
Existem três categorias principais de aprendizado de máquina: supervisionado, não supervisionado e por reforço.
1. Aprendizado Supervisionado
Este é o tipo mais comum, onde o algoritmo se instrui a partir de um conjunto de dados rotulado. A finalidade é identificar uma função que relaciona entradas a saídas. Exemplos incluem regressão linear e máquinas de vetores de suporte.
2. Aprendizado Não Supervisionado
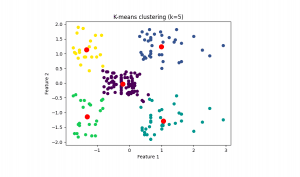
Aqui, o algoritmo é treinado em dados não rotulados, sendo incumbido de descobrir padrões intrínsecos. Algoritmos de clustering e técnicas de redução de dimensionalidade são exemplos nesse contexto.
3. Aprendizado por Reforço
Nesse cenário, um agente aprende a otimizar seu comportamento em um ambiente para maximizar recompensas acumulativas. Aplicações incluem sistemas de recomendação e estratégias de navegação para robôs.
Etapa Crucial: Preparação de Dados
1. A Essencial Preparação de Dados
Antes de adentrarmos nos algoritmos de aprendizado de máquina, a compreensão da importância da preparação de dados é imperativa. O ditado “Lixo entra, lixo sai” ressalta que a qualidade dos insights gerados é diretamente proporcional à qualidade dos dados.
2. Limpeza de Dados
A primeira etapa consiste na limpeza dos dados, envolvendo remoção ou correção de imprecisões, incompletudes ou irrelevâncias. Técnicas como tratamento de valores ausentes e remoção de outliers são fundamentais nesse processo.
3. Transformação de Dados
Após a limpeza, a transformação de dados se faz necessária, abrangendo técnicas como normalização, padronização e codificação de variáveis categóricas.
4. Divisão de Dados
A etapa final envolve a divisão dos dados em conjuntos de treinamento e teste, ou, ocasionalmente, validação. Essa prática possibilita a avaliação do desempenho do modelo em dados não vistos, garantindo uma modelagem mais robusta e precisa.
A preparação de dados é essencial para o sucesso na modelagem de aprendizado de máquina, garantindo eficiência e acurácia nos resultados.
Explorando Algoritmos de Aprendizado de Máquina
1. Regressão Linear
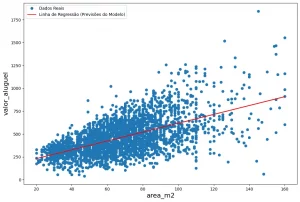
A Regressão Linear, algoritmo supervisionado, analisa relações entre variáveis e prevê resultados futuros com base em dados históricos. É aplicável em análise de tendências, sendo útil para decisões informadas durante transações.
2. Árvores de Decisão
Árvores de Decisão resolvem problemas de classificação e regressão, dividindo iterativamente dados com base em características. São valiosas na análise de relações entre variáveis e na identificação de fatores-chave em resultados.
3. K-Vizinhos mais Próximos (KNN)
O algoritmo KNN, supervisionado, prevê classificações ou valores baseando-se na proximidade de pontos de dados. Aplicável na previsão de comportamento de mercado e identificação de padrões com base em históricos.
4. Redes Neurais Artificiais
Inspiradas no cérebro humano, as Redes Neurais Artificiais possuem camadas de neurônios que processam informações e aprendem com dados de entrada. Adequadas para prever preços, detectar fraudes e otimizar estratégias de negociação.
Exploramos quatro algoritmos amplamente utilizados na análise de dados, destacando sua aplicabilidade no contexto de negociação. O entendimento dessas técnicas proporciona vantagem competitiva e decisões mais informadas.
Aprofundando nos Modelos de Aprendizado de Máquina
1. Validação de Modelos
A validação de modelos é essencial para avaliar o desempenho do modelo treinado. Técnicas incluem a divisão de dados em conjuntos de treinamento e teste, validação cruzada k-fold e validação cruzada de repetição aleatória.
2. Otimização de Hiperparâmetros
Hiperparâmetros, definidos antes do treinamento, impactam o desempenho do modelo. A otimização envolve testar diferentes combinações de valores, utilizando técnicas como pesquisa em grade, pesquisa aleatória e otimização bayesiana.
3. Seleção de Recursos
Identificar e selecionar os recursos mais relevantes melhora a eficiência e precisão do modelo. Técnicas incluem filtragem, seleção baseada em envoltório e seleção baseada em incorporação.
4. Aplicação e Avaliação em Dados Reais
Após treinamento e otimização, aplicar o modelo a dados reais é crucial. Métricas como precisão, recall, F1-score e erro médio quadrático são utilizadas para avaliar o desempenho, considerando também interpretabilidade e facilidade de implementação.
A validação de modelos, otimização de hiperparâmetros, seleção de recursos e aplicação em dados reais são fundamentais para garantir eficácia e confiabilidade em modelos de aprendizado de máquina no contexto de negociação.
Referências:
- https://awari.com.br