
Detalhes do projeto
- Link do projeto no Github: https://github.com/cerqueiralex/chatgpt-analise-de-sentimentos
- Tecnologias: Python, OpenAI API, CSV, Matplotlib, Json
- Categorias: DataScience, Prompt Engineering
Atualmente a maior parte dos processos seletivos das empresas (principalmente no setor de tecnologia) utiliza algum software para conduzir os processos e coletar feedbacks dos candidatos com a finalidade de entender quais foram as possíveis falhas e a partir disso como melhorar a abordagem ou alguma etapa específica da entrevista.
Uma abordagem inovadora para aprimorar esse processo é a análise de sentimentos. Por meio da análise automatizada de textos, como currículos, entrevistas e feedbacks, é possível obter insights valiosos sobre as opiniões e emoções dos candidatos, auxiliando as empresas a tomarem decisões mais informadas.
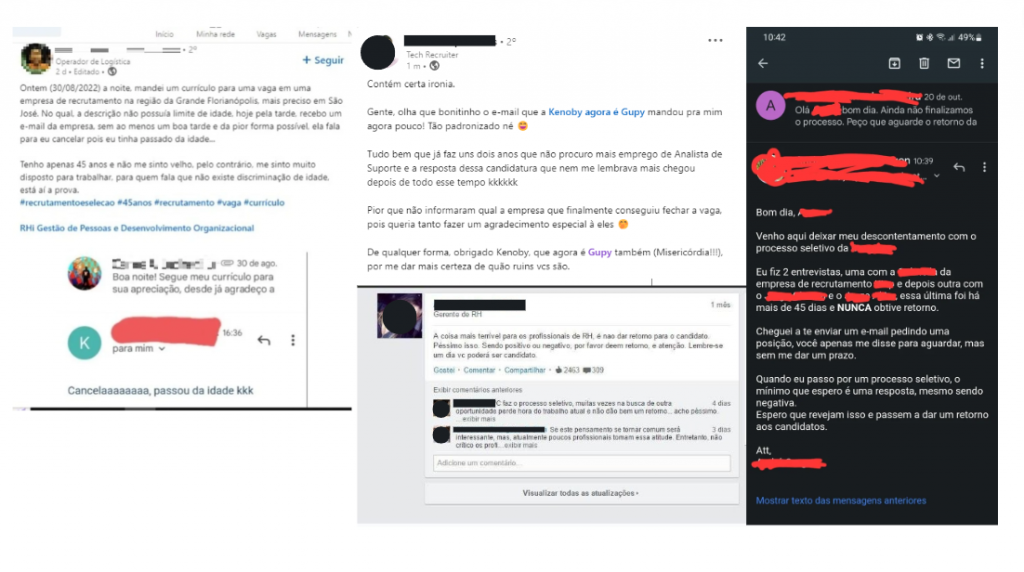
Neste artigo, apresento um projeto em Python para realizar a análise de sentimentos em um processo de recrutamento de RH para uma empresa de tecnologia que utiliza como motor o ChatGPT 3.5 e apresenta o resultado da análise em gráficos utilizando Matplotlib.
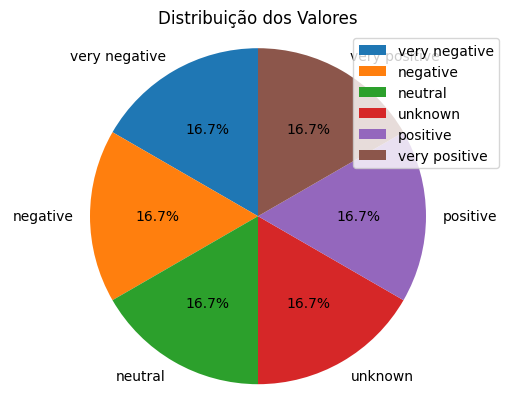
O resultado final pode ser um gráfico que mostra por exemplo as porcentagens de cada tipo de sentimento analisado no conjunto de dados.
Claramente esse essa estrutura pode ser adaptada e utilizada em diversos contextos diferentes, mas aqui iremos escolher um foco que é o feedback para processos de recrutamento em setores de RH.
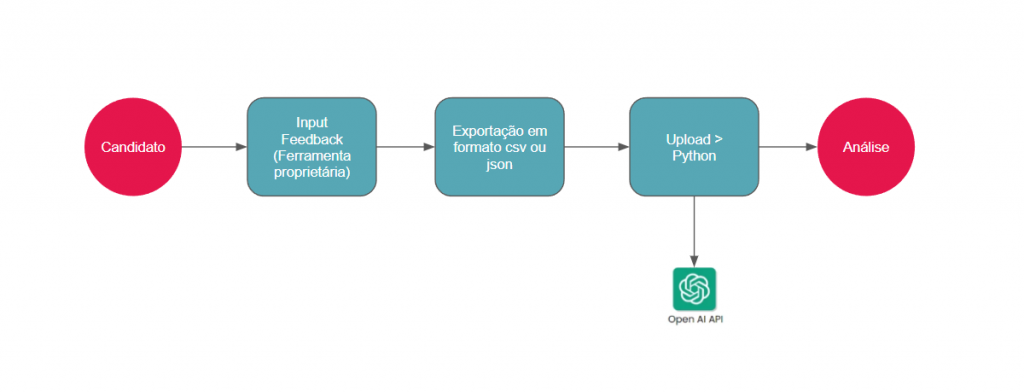
Neste projeto, a ideia de estrutura é que em algum momento do processo seletivo seja enviado um sistema para que os candidatos possam enviar o seu respectivo feedback (de preferência em modo anônimo) e então com esse feedback nós tratamos e subimos no python para gerar as análises.
Open AI e ChatGPT
Instalamos então nossas bibliotecas que serão utilizadas para o programa. Primeiramente o pacote da openai que irá importar o ChatGPT responsável pela análise de sentimentos.
!pip install openai
!pip install load_dotenvimport openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # Ler o arquivo .env local.
openai.api_key = ('SUA CHAVE DA API OPENAI AQUI')O código em questão é uma importação das bibliotecas openai e dotenv e faz uso da função load_dotenv para carregar variáveis de ambiente de um arquivo .env local.
A biblioteca openai é um pacote Python fornecido pela OpenAI, que permite interagir com os serviços e modelos oferecidos pela plataforma. A linha de código openai.api_key = ('') define a chave de API do OpenAI que será usada para autenticação e acesso aos recursos. É necessário substituir pela sua própria chave obviamente.
A biblioteca dotenv é utilizada para carregar variáveis de ambiente de um arquivo .env. O arquivo .env é um arquivo de configuração que contém informações sensíveis, como chaves de API, que não devem ser expostas diretamente no código pois a openai possui uma política automática de detecção de exposição de chaves api em diretórios públicos e se sua chave for exposta ela é cancelada automaticamente e você irá precisar gerar uma nova.
A função load_dotenv() carrega as variáveis de ambiente do arquivo .env e as torna disponíveis para o programa. O uso do _ antes de load_dotenv() é uma convenção comum para indicar que não estamos interessados no valor de retorno da função, apenas na sua execução.
Em resumo, o código importa as bibliotecas necessárias, carrega as variáveis de ambiente de um arquivo .env e define a chave de API do OpenAI para uso posterior nas interações com a plataforma.
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # Este é o grau de aleatoriedade da saída do modelo.
)
return response.choices[0].message["content"]Aqui definimos uma função chamada get_completion em Python. Essa função recebe dois parâmetros: prompt e model. O valor padrão para o parâmetro model é “gpt-3.5-turbo”.
De forma resumida, a função get_completion recebe um prompt e um modelo como entrada, envia o prompt para o modelo usando a API de Chat Completion da OpenAI e retorna a resposta gerada pelo modelo.
Dentro da função, é criada uma lista chamada messages contendo um dicionário. O dicionário representa uma mensagem de usuário no formato esperado pela API de Chat Completion da OpenAI. O valor da chave “role” é definido como “user” e o valor da chave “content” é definido como o valor do parâmetro prompt recebido pela função.
Em seguida, é feita uma chamada à API de Chat Completion da OpenAI usando a função openai.ChatCompletion.create(). O modelo especificado é o valor do parâmetro model. A lista messages é passada como valor para o parâmetro messages, e o parâmetro temperature é definido como 0, que significa que a saída do modelo será mais determinística, com menos aleatoriedade.
A resposta da API é armazenada na variável response. Através dessa resposta, é possível acessar as escolhas feitas pelo modelo usando response.choices. No código, é retornado o conteúdo da primeira mensagem da primeira escolha, que é acessado através de response.choices[0].message["content"].
Carregando o arquivo com o feedback dos candidatos
Como vamos trabalhar com o feedback dos candidatos, nesse caso aqui pensei num formato simples que carrega um csv e posteriormente trata esse csv para transformá-lo em um json para ser utilizado em ferramentas de data science.

Esse é um exemplo de conjunto de dados fictício que deixa as emoções e sentimentos em relação ao processo bem evidentes.
import csvnome_arquivo = 'arquivo_com_os_feedbacks.csv'
# Abre o arquivo CSV e cria o objeto leitor
with open(nome_arquivo, 'r') as arquivo_csv:
leitor = csv.reader(arquivo_csv)
# Transforma os dados do leitor em uma lista
reviews = list(leitor)Primeiro, é definida uma variável nome_arquivo que contém o nome do arquivo CSV a ser lido.
O código lê um arquivo CSV, percorre suas linhas e armazena os dados em uma lista chamada reviews.
Utilizamos a declaração with open(nome_arquivo, 'r') as arquivo_csv para abrir o arquivo CSV no modo de leitura ('r'). Essa forma de abrir o arquivo dentro do bloco with garante que o arquivo será fechado corretamente após o uso, mesmo em caso de exceção.
Dentro do bloco with, é criado um objeto leitor de CSV usando a função csv.reader(), passando o arquivo CSV aberto como argumento. Esse objeto leitor permite percorrer as linhas do arquivo CSV.
O próximo passo é converter os dados do objeto leitor em uma lista. Isso é feito utilizando a função list(), que recebe o objeto leitor como argumento. Ao converter o objeto leitor em uma lista, obtemos uma lista de listas, onde cada lista interna representa uma linha do arquivo CSV.
#JSON Formatting
prompt = f"""
Identify the following items from each item in the reviews list:
- The ID for each respective review, starting with 0
- Sentiment (very positive, positive, neutral, negative or very negative)
- Is the reviewer expressing anger? (true or false)
- A list of emotions that the writer of the review is expressing
The reviews list is delimited with triple backticks.
Format your response as a JSON object with "ID, "Sentiment", "Anger" and "Emotions" as the keys.
If the information isn't present, use "unknown" as the value.
Make your response as short as possible.
Format the Anger value as a boolean.
Dont write more than 5 emotions
Reviews list: '''{reviews}'''
"""
response = get_completion(prompt)
print(response)Agora colocamos o motor do ChatGPT para brilhar!
Como é possível ver na prompt, eu utilizei algumas requisições simples, mas é possível solicitar diversas outras análises e tratamentos para serem gerados com os feedbacks.
Nesse caso vou definir um ID para cada feedback para formatar um objeto json, o sentimento identificado pelo ChatGPT, se a review está expressando raiva (retorna de forma boolean) e uma lista de palavras chave que forem identificadas como emoção.
Esse é o resultado de um arquivo fictício que alimentei para testar o comportamento do modelo em todas as 6 variações de sentimentos que defini:
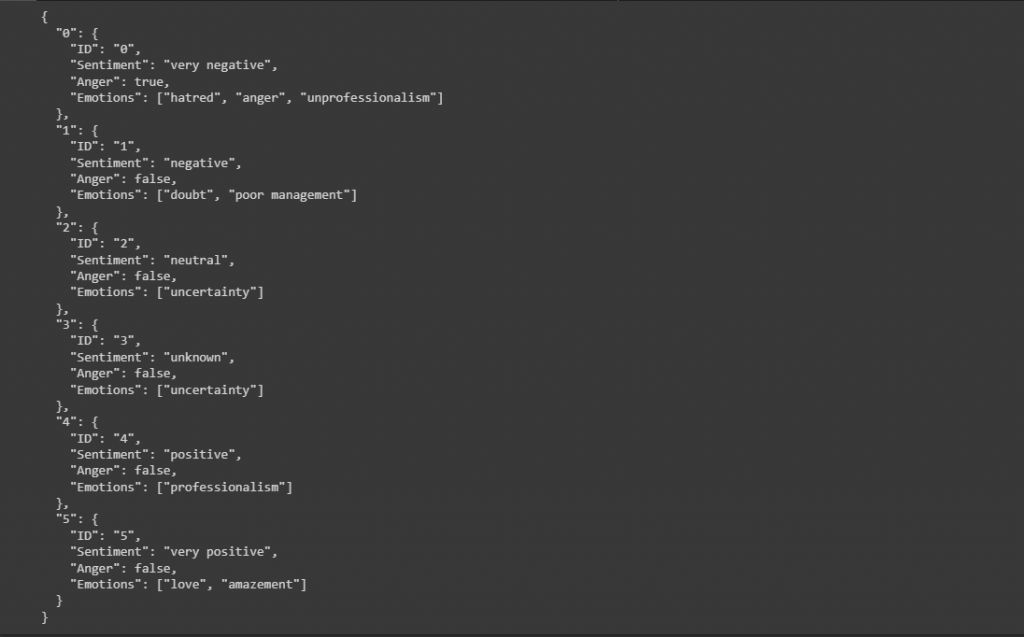
Visualização dos resultados
import matplotlib.pyplot as plt
import json as jsVamos utilizar o pacote Matplotlib para gerar os gráficos e o json para adequar os dados para o Matplotlib
data_json = js.loads(response)Realizamos a conversão de uma string JSON em um objeto Python utilizando a função loads() do módulo json.
O código converte uma string JSON em um objeto Python, permitindo que os dados do JSON sejam manipulados e acessados facilmente no programa Python.
# Inicializar o dicionário para armazenar as contagens
xyz = {}
# Calcular a quantidade de cada tipo de valor dentro da chave 'Sentiment'
for item in data_json.values():
sentiment = item['Sentiment']
if sentiment in xyz:
xyz[sentiment] += 1
else:
xyz[sentiment] = 1
print(xyz)Fazemos a contagem da quantidade de cada tipo de valor dentro da chave ‘Sentiment’ em um dicionário data_json e armazena os resultados no dicionário xyz.
Depois percorremos os valores de um dicionário data_json, conta a quantidade de cada tipo de valor dentro da chave ‘Sentiment’ e armazena os resultados em um novo dicionário xyz.
# Preparar os dados para o gráfico de pizza
labels = list(xyz.keys())
values = list(xyz.values())
# Criar o gráfico de pizza
fig, ax = plt.subplots()
ax.pie(values, labels=labels, autopct='%1.1f%%', startangle=90)
# Ajustar aspectos visuais
ax.axis('equal') # Torna o gráfico circular
plt.title('Distribuição dos Valores')
plt.legend()
# Exibir o gráfico
plt.show()
O resultado final aqui é uma visualização simples da porcentagem de cada tipo de sentimento. Podemos gerar outras análises também.
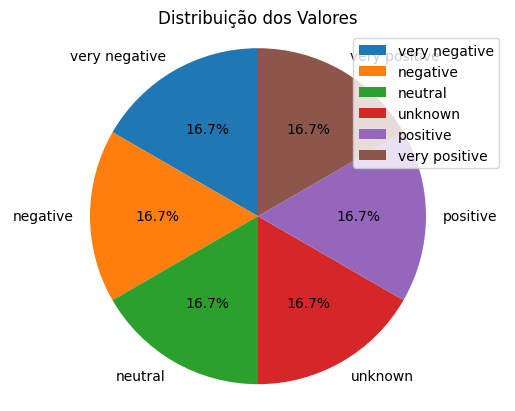
Para uma análise mais granular dos resultados, utilizamos o json gerado lá atras que nos trás os outputs do nosso modelo de sentimentos do GPT e quais emoções ele captou de cada feedback.

Repositório Github
O código completo está disponível no seguinte repositório do Github:
https://github.com/cerqueiralex/chatgpt-analise-de-sentimentos

